
Veinte anglicismos nuevos cada día
La lingüista computacional Elena Álvarez Mellado (Madrid, 33 años) ha creado una herramienta que permite encontrar los anglicismos publicados cada día en los medios informativos. Se denomina Observatorio Lázaro, en recuerdo del exdirector de la Real Academia Española Fernando Lázaro Carreter. Aunque el sistema aún está en fase de desarrollo, ya ofrece algunos resultados. Por ejemplo, el estudio diario de ocho medios españoles muestra que entre todos ellos publican unos 400 anglicismos cada día, de los que 200 no están repetidos y 20 no habían sido detectados anteriormente por el modelo. De esos 400 anglicismos diarios, elpais.com acoge 90 (cómputo sobre septiembre y octubre).
Álvarez Mellado recopila estos datos desde abril de 2020, si bien comenzó sus trabajos en diciembre de 2019. En estos siete meses ha contabilizado más de 70.000 anglicismos en esas ocho cabeceras.
Se puede acceder al programa en esta dirección: https://observatoriolazaro.es.
Los medios analizados son elpais.com, elDiario.es, elmundo.es, abc.es, lavanguardia.com, elconfidencial.com, 20minutos.es y efe.com. El programa, un modelo de aprendizaje automático, no toma como anglicismos, deliberadamente, ni los nombres propios ni los términos de origen inglés que han sido incorporados en redonda al Diccionario de la lengua española, el publicado por las academias. Por ejemplo, excluye palabras como web o bar (del inglés bar, barra). Y, por otro lado, la herramienta informática (que analiza solamente los textos informativos de libre acceso) considera a veces como anglicismos, por error, algunos vocablos que no lo son en realidad, como los títulos en inglés de películas o de libros.
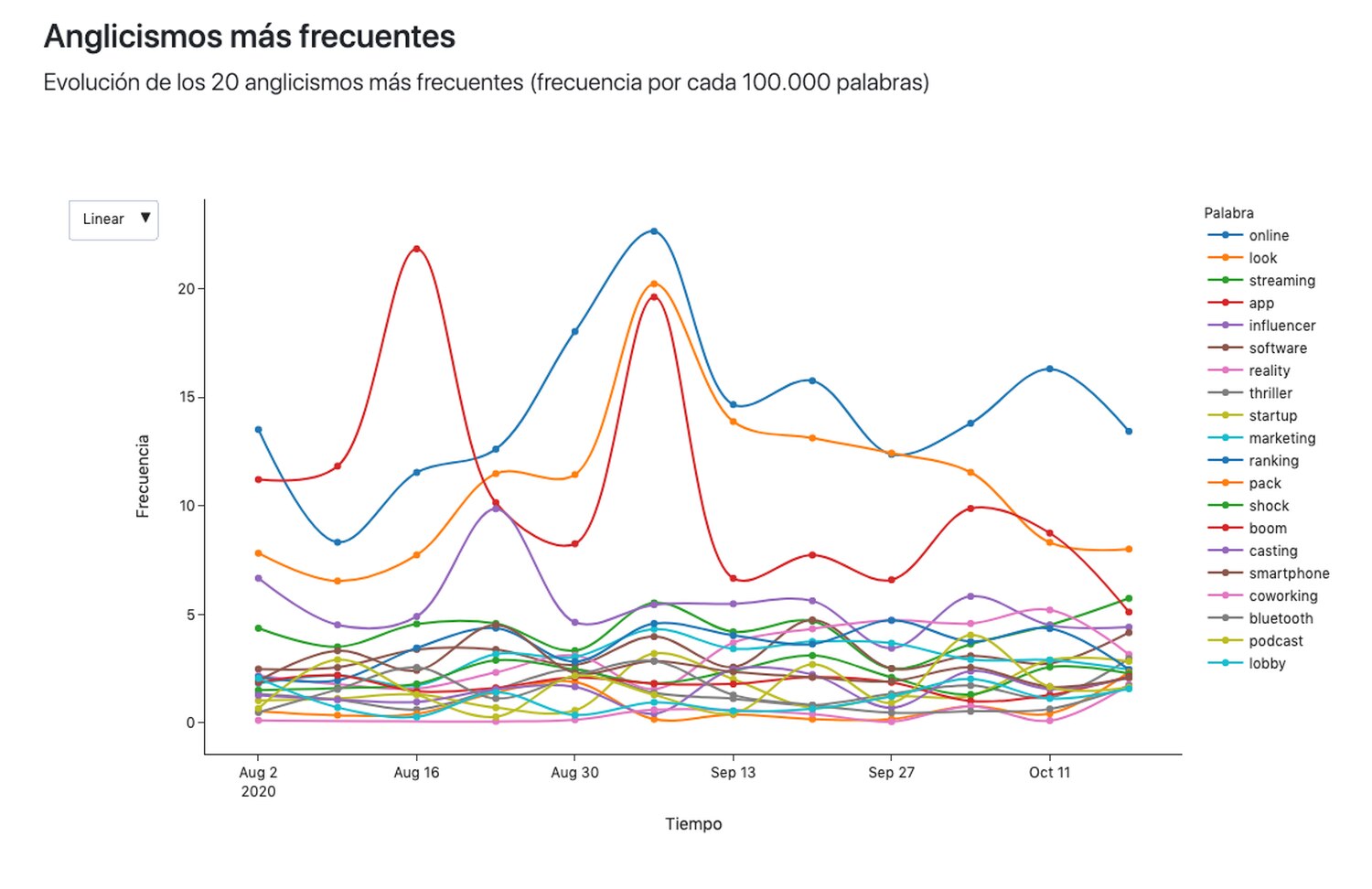
Los anglicismos más repetidos la pasada semana en esos ocho medios fueron online, look, app (los tres con una frecuencia de entre 10 y 20 registros por cada 100.000 palabras), streaming, influencer, software, reality, thriller, start-up, marketing, ranking, pack, shock, boom, casting, smartphone, coworking, bluetooth, podcast y lobby.
Entre los que más crecieron en ese período y van alcanzando lugares de cabeza figuran rider, revolving, filming day, low cost, youtuber, town hall o rave.
elpais.com publicó en esos siete días algunos de los 140 anglicismos nuevos que aparecen cada semana: family banker, identity politics, spring semester, happy new society, feels good, no fly list, growshop, alley oop, just tired, baked beans, long sellers, backwaters, feminism washing, snippets, full back, team building, deluxe edition, booktoubers, mixed feeling, new school… y otros muchos.
Los cuadros que proporciona el sistema recogen el título del artículo, la fecha y el enlace correspondiente.
Álvarez Mellado aclara que el objetivo de Observatorio Lázaro no es defender una supuesta pureza lingüística del español, sino estudiar el fenómeno del préstamo léxico en la prensa de forma empírica y con una perspectiva basada en datos. “Mi objetivo”, señala, “es hacer observaciones más generales cuando tenga más meses de evolución acumulados, analizar qué anglicismos entran, cómo se asientan, etcétera”.
Su proyecto previo al desarrollo práctico del Observatorio Lázaro recibió el premio Outstanding Corpus Thesis Award (premio de tesis de corpus excepcional) del Institute for Corpus Research (Instituto de Investigación de Corpus) de la Universidad Nacional de Incheon (Corea del Sur) y el premio Karen Spärck Jones Award for Outstanding Achievement in Natural Language Processing (premio al logro sobresaliente en el procesamiento del lenguaje natural) de la Universidad de Brandeis (Massachusetts). Se denomina “corpus” en lingüística a los textos reunidos en una base de datos extensa y ordenada que sirve como punto de partida para una investigación.
El germen del proyecto fue desarrollado en el Computational Structure of Language Lab (laboratorio de estructura computacional de idiomas) de la Universidad de Brandeis (Massachusetts) bajo la supervisión del profesor Constantine Lignos.
Elena Álvarez Mellado ha desarrollado previamente el proyecto Aracne para la Fundéu (sobre la riqueza léxica en los medios informativos) y trabajó como lingüista computacional para Molino de Ideas (empresa dedicada al procesamiento lingüístico).
Actualmente es programadora de investigación en el Instituto de Ciencias de la Información de la Universidad del Sur de California. Ha publicado el libro de divulgación lingüística Anatomía de la lengua, colabora periódicamente en la revista Archiletras y en elDiario.es, y obtuvo en 2018 el premio Miguel Delibes por una columna en este último medio.